In this week´s post we will take a good look at an old feature that in the version 2310 of Simcenter STAR-CCM+ got an update. I am talking about the surface wrapper, and the fact that it has now been partly parallelized. The general difficulty in improving and speeding up an algorithm, especially one that is related to meshing, is that a new and updated feature needs to be able to reproduce more or less what the old one did. Now, the wrapper should provide a reduced CAD-to-mesh time via distributed memory (MPI) parallelization of the surface wrapper.
We will go over the test that Siemens has done on this and present their findings. We will also look at a test that I have done comparing the wrapper wall time for some different wrapper settings in a test case. But first, we will go over what the wrapper is and what it does.
Surface Wrapper
The surface wrapper is a quick and relatively easy way to reduce the geometry input to a closed and manifold fluid (or solid) domain. It can be used if you have more parts than you wish to handle, if you have broken geometry input with holes and such. It can also be used when you have duplicate surfaces. I have previously written about the surface wrapper in the posts; Gap closure in the surface wrapper – VOLUPE Software and How to use Surface Wrapper Defeature and Contact prevention controls – VOLUPE Software. Using the surface wrapper can be seen as applying cling film to an object, in smooth areas, as it will be smooth and follow what is under, but in areas with much detail, the result might be somewhat simplified. You can use the surface wrapper to keep or reduce the level of output that you use in your simulation.

MPI wrapper (Siemens)
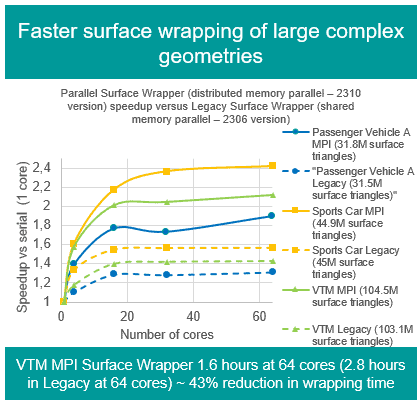
The news for Simcenter STAR-CCM+ version 2310 is that the surface wrapper has been partially parallelized in this release, with more to come later. The parts that are now parallelized are the steps up to gap closure, including parallel octree generation, the gap closure, contact prevention as well as parallel octree for leak detection. The MPI wrapper can offer up to 43% reduction in wrapper wall time compared to legacy.
The new MPI gap closure offers an improved placement of gap closure faces for a better mesh quality and can better utilize the input of e.g., gap closure size. It is important to note that it will still be possible to use the legacy wrapper via a tick-box in the wrapper operation. Features that still require the legacy wrapper are “Local surface wrapping” and “Partial surface wrapping”. Below we can see a comparison between the Legacy surface wrapper and the MPI surface wrapper when it comes to gap closure.
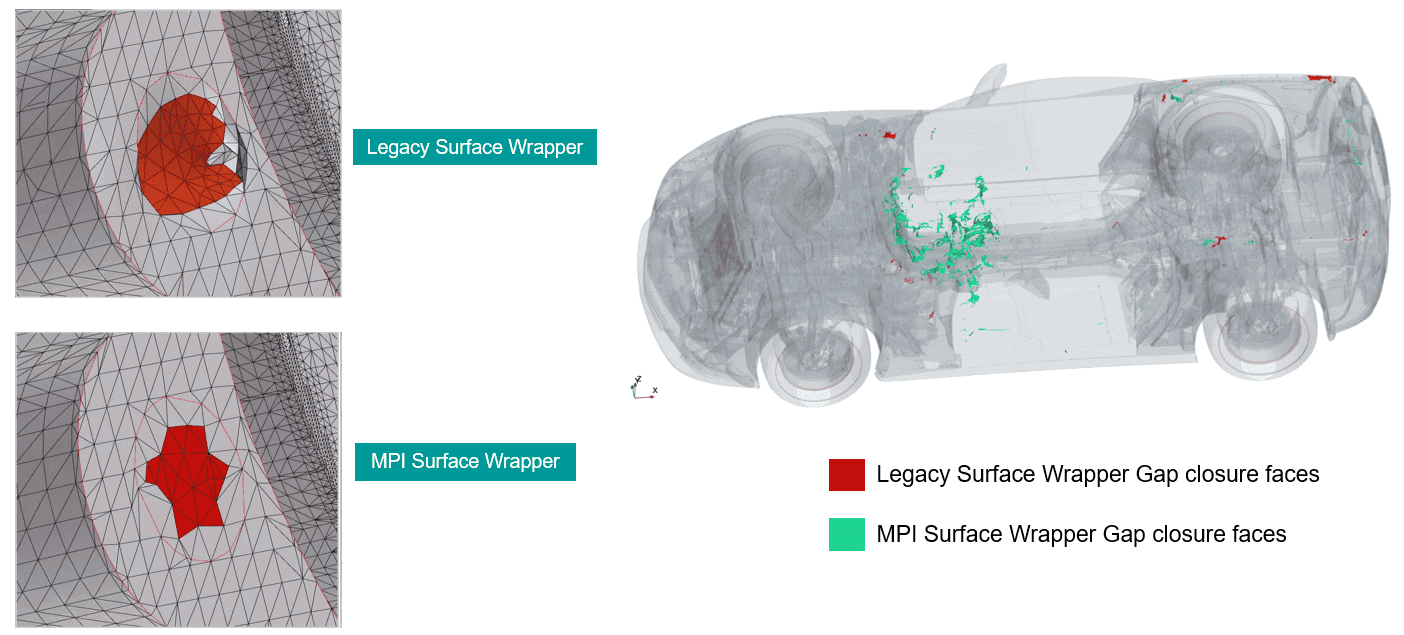
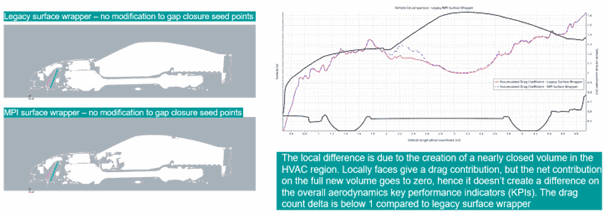
The difference in result will impact the end result and the MPI wrapper will have a leak inside the HVAC-unit, which will locally give a contribution to drag from surfaces. However, the net contribution on the full volume goes to zero.
This can be remedied by adding three additional gap closure seed points when using the MPI wrapper.
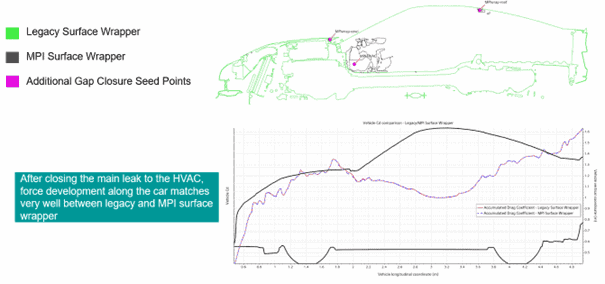
Since there are differences in the result, it should be investigated when changing an old case and using it with the new wrapper, what impact that might have on the result.
The Volupe test of the MPI wrapper
We will revisit an old favorite when it comes to meshing and wrapping, the somewhat simplified Range Rover car. As you can see from the picture below the car has on the top side many of the features of a real car, but the underside of the car is simplified. There is no under hood part, the grill area is closed.

The wrapping procedure of the car is set up using several custom controls, including curve controls, volumetric control, and surface controls. Combined with that we also have several two-group contact prevention sets to refine the output between specific parts, like the windshield and the wipers, or the wheels and the road. The base size of the operation is 2.5 cm with 100% target and 10% minimum surface size. The gap closure size is at 10% of base size.
The bulk part of the test was performed on my laptop, with between 1 and 8 cores. With a processor that is 11th Gen Intel® Core™ i9-11950H @ 2.60 GHz and 128 GB of RAM, in a Windows environment. All tests were performed with Simcenter STAR-CCM+ 2310 R8 (double precision). Below are the results in the table and graph.
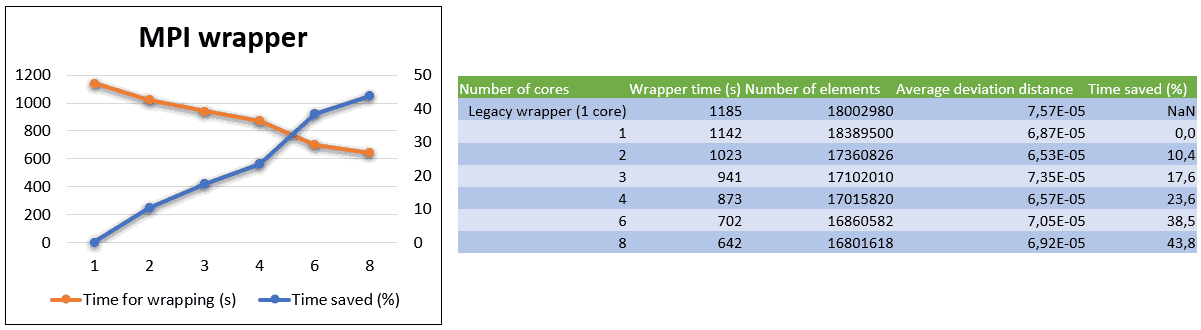
We can see that going from 1 to 8 cores saves almost 44% of time. That is in line with Siemens reported values. Additionally, the table shows the number of elements produced by the wrapper in each procedure as well as the surface average deviation distance from the CAD. In general, it seems like more cores lead to less elements produced without any clear trend for deviation distance. Adding more cores (hyperthreading) gave an increase in time, meaning that running on 10 cores (with only 8 physical cores) gave a wrapping time of 740 s. Thay shows that we don’t get a diminishing return using the wrapper with hyperthreading, but rather an increase in time. This emphasizes the recommendation of NOT using hyperthreading.
Additionally, a test was performed where all custom controls and all contact preventions was disabled, but left was the gap closure. In this test the base size was reduced down to 0.5 cm. This was done on 1 and 8 cores, with the results of 4530 s and 2456 s respectively. A time saving of 43.3 % was achieved, which is a value in line with the previous test.
I hope this has been useful to you, and that you can save some time in meshing pipeline when using the new MPI wrapper. If you have any questions, as usual reach out to support@volupe.com.
Author

Robin Victor
+46731473121
support@volupe.com