Introducing a Dedicated Surrogate Tab
Simcenter HEEDS 2504 brings a major leap forward in surrogate modelling with a dedicated Surrogates tab that centralizes all relevant tools and visualizations. No more jumping between menus, everything you need to build, tune, and evaluate surrogate models is now in one streamlined interface.
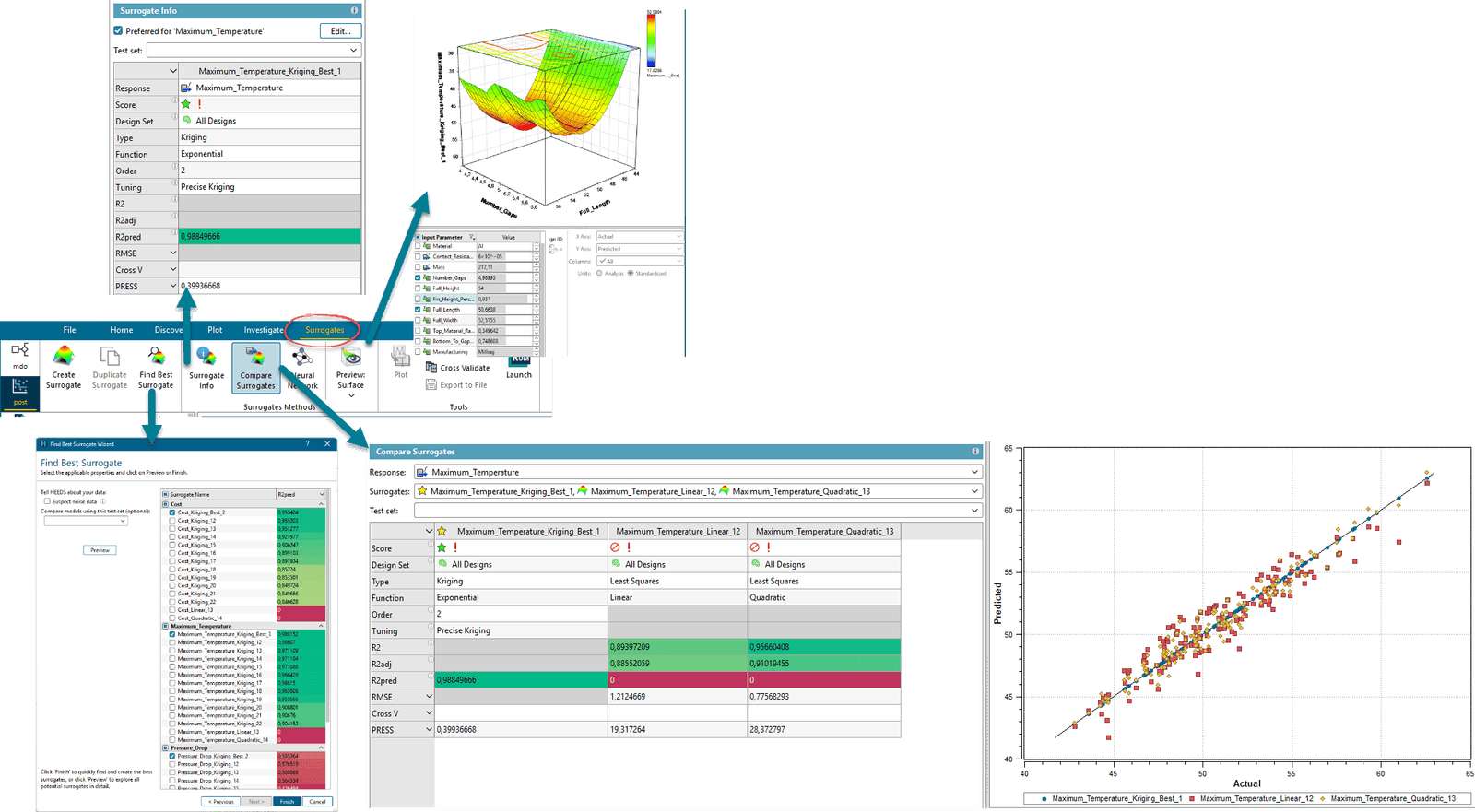
The newly introduced Surrogates tab consolidates various previously dispersed tools, such as Neural Network creation, Simcenter Reduced Order Modelling activation, surrogate visualization, validation operations, and recompute functionality.
Two powerful new widgets enhance the surrogate modelling experience:
- Surrogate Info Widget: Enables quick assessment of the quality and characteristics of each surrogate model, with visual representations of accuracy, fit statistics, and response behavior.
- Compare Surrogates Widget: Allows simultaneous visualization of multiple surrogate models for a given response, to quickly identify the best performing surrogate for specific requirements.
Find the best Surrogate fit
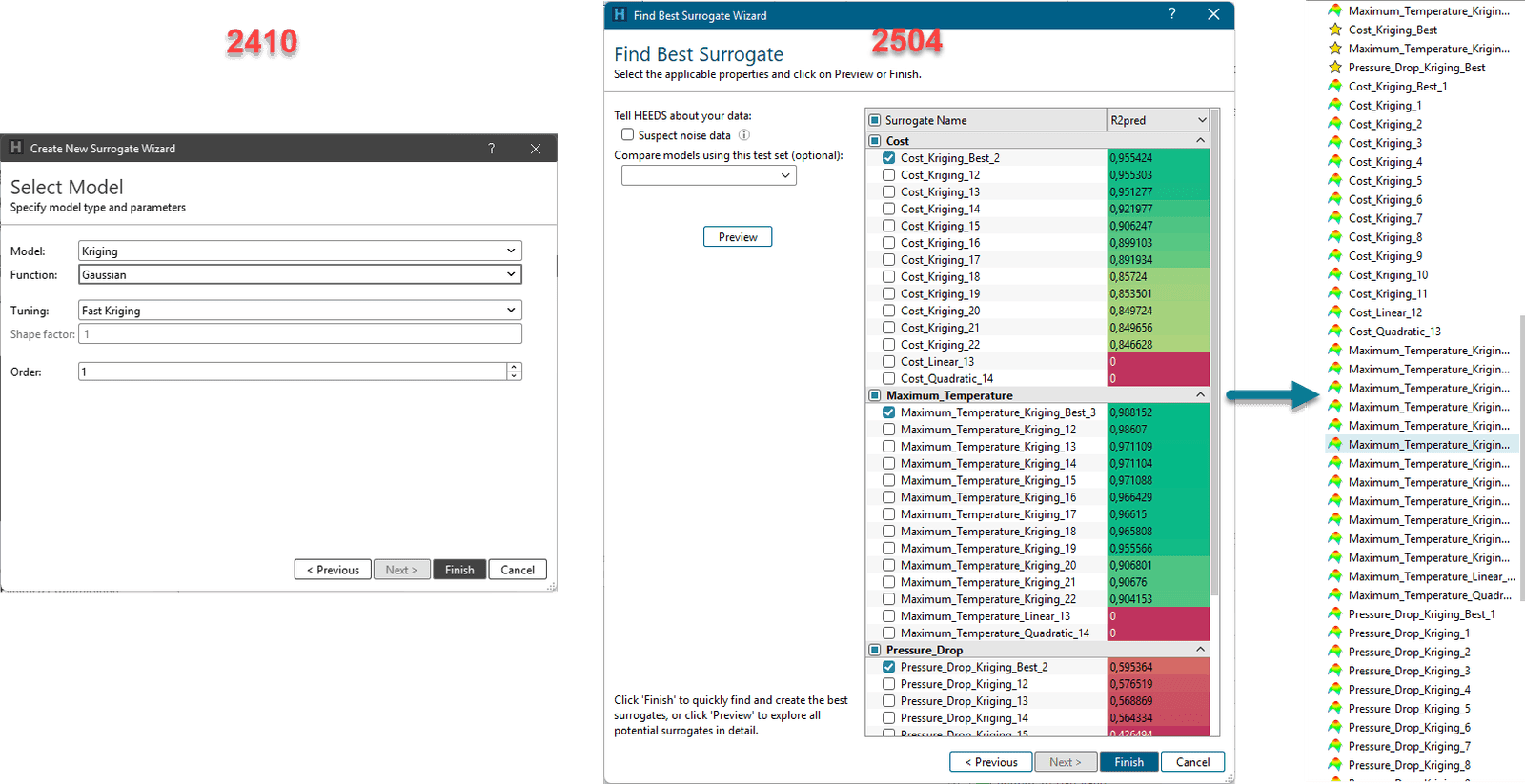
Creating accurate surrogate models previously required significant expertise and time investment. Often several surrogates needed to be manually constructed to compare the effect of “Function” and its “Tuning” on the performance metrics. This process involves considerable trial and error.
The new “Find Best Surrogate” tool systematically explores various surrogate modeling approaches, including polynomial models, radial basis functions, and Kriging methods. It automatically adjusts parameters and configurations to optimize accuracy, evaluating each generated model using statistical criteria (e.g. coefficient of determination) to determine which provides the most accurate representation of the underlying data. The tested surrogates will be created directly from the tool and their performance can be compared with the new Compare Surrogates Widget.
Enhanced Data Set Quality
The accuracy of your created surrogate strongly depends on the quality of the input data. Outliers caused by simulation errors or numerical instability can lead to inaccurate models, misleading visualizations and skewed statistical interpretations. This is why the new release introduces sophisticated clustering techniques to identify and manage outlier designs automatically.
The enhanced Discover Design Clusters method analyses the multi-dimensional design space to identify statistically anomalous points and creates refined design sets that exclude these outliers. This allows you to easily create new design sets with outliers removed.
Boruta Influence updates
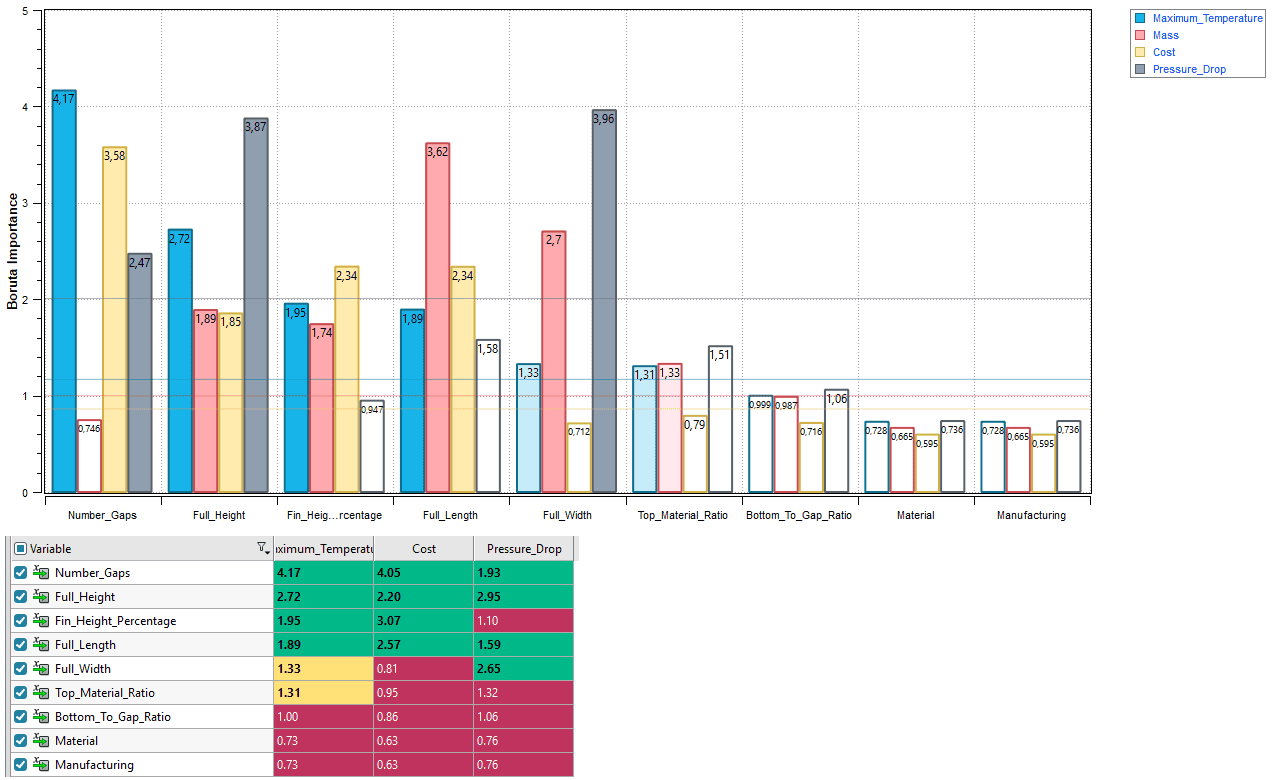
HEEDS 2504 introduces significant improvements to the Boruta variable importance visualization. The enhancement features intuitive shading that immediately highlights the most important variables, allowing us to quickly identify key design factors without detailed analysis.
The visualization has been refined to remove negative values from the bar chart, providing a cleaner, more straightforward representation of variable importance. Variables are now clearly categorized and visually distinguished within the plots, enhancing readability and interpretability.
Praxis Check: Do These New Tools Really Make a Difference?
To find out, we ran a heat sink optimization focused on minimizing temperature (CFD analysis) and manufacturing costs (Excel chart). We started with a design space exploration using Adaptive Sampling.
Step 1: Eliminate Noise
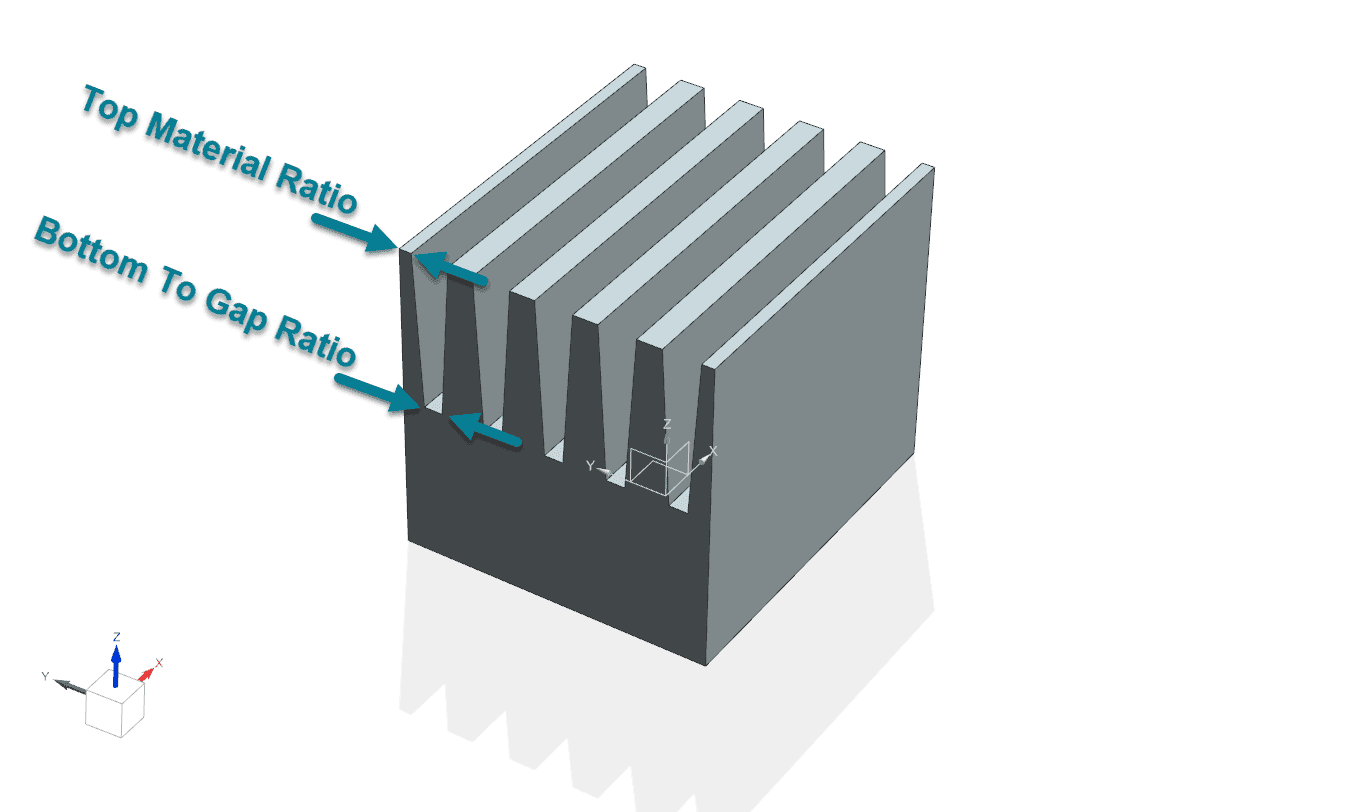
Using the improved Boruta analysis, we identified and excluded parameters with minimal impact on our objectives (Max Temperature, Cost) based on CFD results from Simcenter STAR-CCM+. Four parameters tied to fin root and top geometry, the manufacturing method and material selection were dropped.
Step 2: Clean the Data
Next, we used Design Cluster Discovery to remove outliers. Designs were grouped into clusters using Euclidean distance. Designs which are close to each other in the design space and to the cluster center are clustered. This clustering process repeated, recomputing the cluster center, until stable groups were formed. We selected cluster c1 and removed five outliers for further modelling.
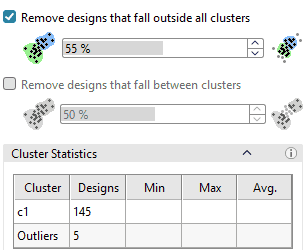
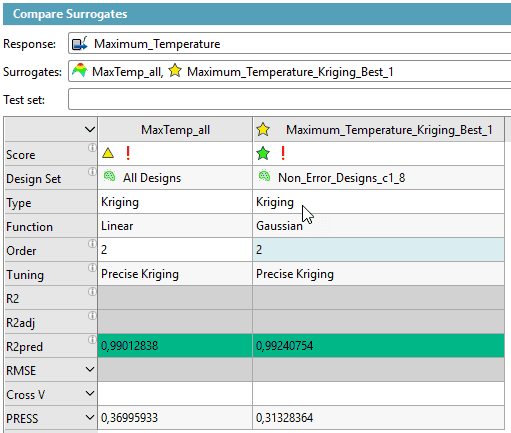
Step 3: Build the Best Surrogate
With the cleaned dataset, we built surrogate models. Even this small change in input data significantly improved model accuracy, as shown in the Compare Surrogates Widget.
We then ran optimization in three ways:
- Full Optimization – using full CFD simulation results
- Optimal Surrogate – based on reduced parameters and clean data
- Plain Surrogate – using all parameters and the original Adaptive Sampling dataset
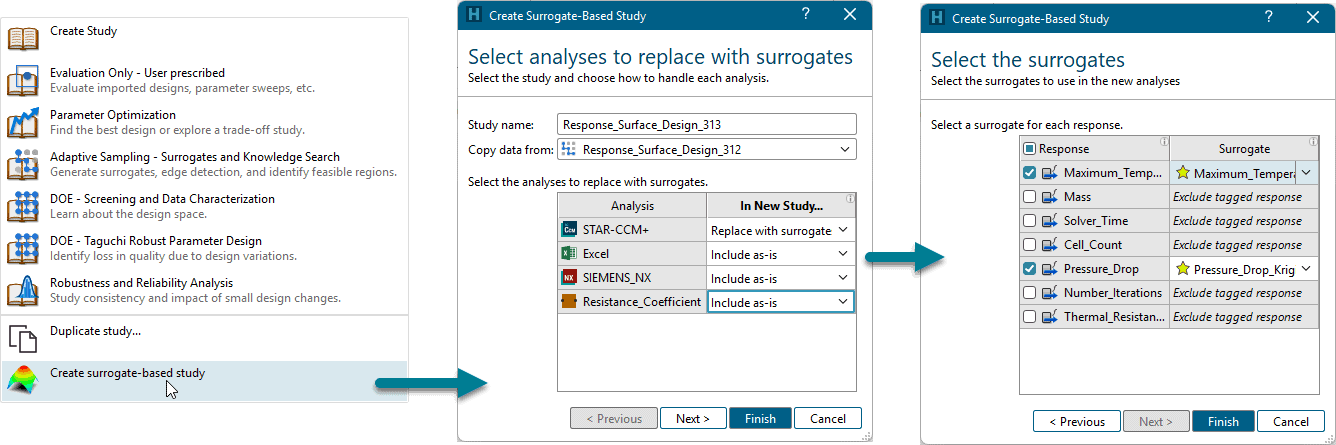
A new Surrogate-based design study can easily be created from the Study dropdown menu. During the definition you can decide which of the analysis shall be replaced with which of the created surrogate models. In our example we replace only the Simcenter STAR-CCM+ evaluation.
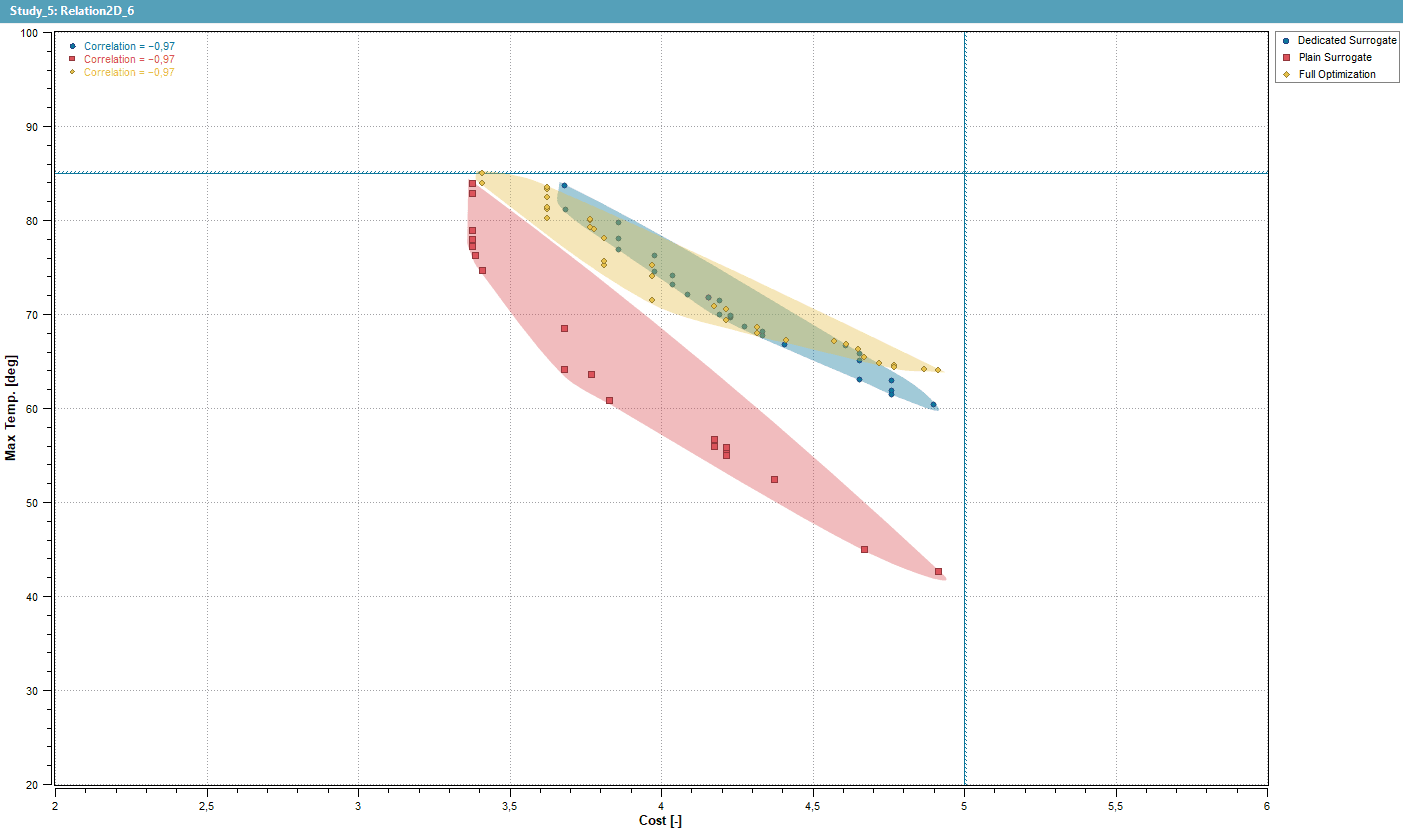
The Outcome
Comparing the final non-dominated fronts, it is obvious that full simulation produced the most optimal results. However, the Optimized Surrogate (reduced + cleaned) came much closer to the simulated results than the Plain Surrogate. The enhancements in HEEDS 2504 clearly helped the surrogate method to approach true Pareto-optimal results, while the plain surrogate large over predicts the improvements. This shows how important the accurate generation of the surrogate model is and the new features in HEEDS contribute immensely.
The Author
Florian Vesting, PhD
Contact: support@volupe.com
+46 768 51 23 46
